

引言:2025年1月15日,美國商務部工業和安全局(BIS)發布了 《人工智能擴散框架》,該框架引入了新的管控物項ECCN 4E091,為人工智能模型參數設定了嚴格的出口管制措施,本文將詳細解讀這一管制物項的含義和適用范圍。
目 錄
一、什么是人工智能模型參數
二、僅限于訓練階段習得的參數
三、模型復雜度限制
四、公開參數模型的排除
1
什么是人工智能模型參數
在現代基于神經網絡的人工智能系統中,“參數”是神經網絡中決定模型行為的核心部分。常見的參數包括權重(weights)和偏置(biases)等。這些參數在訓練過程中被優化,決定了模型的能力和表現。簡單來說,一個訓練完成的人工智能模型,其最直接的結果即為由這些參數組成的結構化數據集。下圖為阿里巴巴集團開源在魔搭社區的“通義千問2.5-7B-Instruct”模型[注1],其中model-00001-of-00004.safetensors等文件即為模型參數文件,為一組機器可讀但人類不可讀的二進制文件。
如果說模型結構是人工智能模型的“靈魂”的話,參數就是這個“靈魂”在經過海量數據的訓練之后得到的“肉身”,是人工智能模型中所凝聚的所有數據、資本和技術的直接體現。
通常來說,用戶取得模型參數后,根據模型結構,即可實現對模型的使用或二次開發。
2
僅限于訓練階段習得的參數
在CCL中,4E091的技術附注(Technical Notes)1中將此處的參數限定為了在訓練階段通過算法習得的參數(如網絡權重、偏置等)。
因此,在訓練前的數據預處理階段(如數據標注、分詞等)所產生的成果,以及非通過訓練習得的超參數(hyperparameters)等,均應不包含在本條目的控制范圍內。
當然,對于超參數其實并不能一概而論,早期AI訓練過程中超參數通常由人為制定,其本身并非可訓練的對象。但隨著技術的發展,在當前的主流AI訓練工作流中,超參數可以通過訓練或優化過程習得。這些超參數在這個層面上并非“固定不變”,而是同樣成為了可訓練的對象,此時超參數就可能落入4E091的范圍。
3
模型復雜度限制
CCL在該管制物項的名稱中即將管制對象限定為使用了超過10^26次“運算”(Operation)的訓練后產生的人工智能模型參數,即該物項不包含BIS認為的“簡單模型”。
(一) 運算量計算
這里的運算是指在模型預訓練或后續訓練(如微調)階段所采取的所有數學運算操作。包括各層的前向傳播、反向傳播、池化,卷積運算等。
CCL的技術附注中給出了一個計算運算量的例子,以一個單層全連接神經網絡(這種情況在工程實踐中非常罕見,僅為一個簡單的例子)為例,其輸入層有I個輸入神經元,輸出層有O個輸出神經元。如下圖所示:
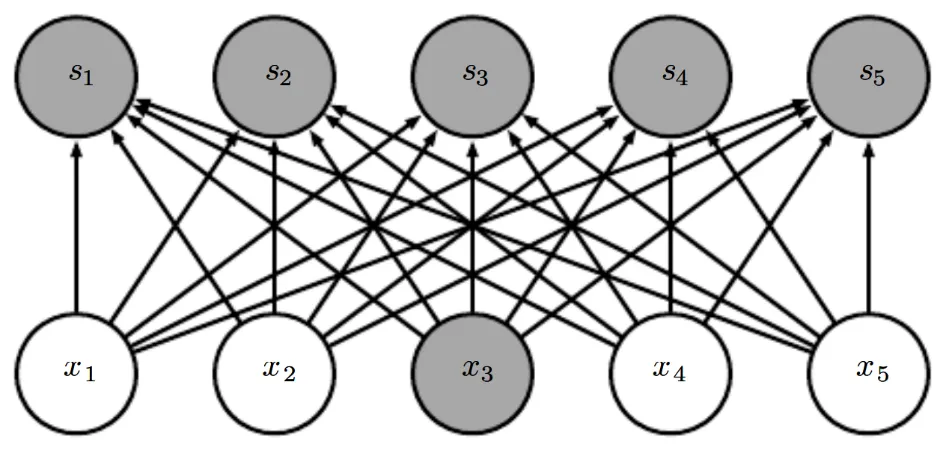
對于這樣的一個神經網絡,其參數量N=I*O,技術附注中的例子還進一步假設了在反向傳播時不對偏置進行計算。則其參數矩陣僅由權重組成,如下圖所示:
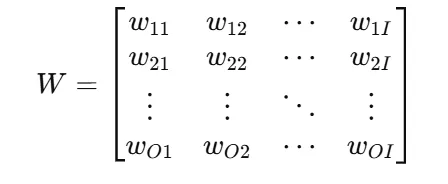
在每一次前向傳播時(從輸入層到輸出層,通常用于計算損失),都需要進行O*I次乘法,并將所有乘法的結果相加,最終總運算次數約等于于2*O*I FLOP(Floating Point Operations)即2N,而每一次反向傳播(即從輸出層到輸入層的反向計算,通常用于更新參數)的總計算量為4N FLOP,即對于前文所屬的簡單神經網絡,對每一個數據點進行的一輪訓練所需要的總計算量為6N FLOP,當總數據量為D時,最終的總計算量即為6ND FLOP。
以上為CCL給出的一個簡單算例,但需要注意的是,前述6ND的結果僅適用于算例中提到的單層全連接神經網絡,工程中具有實用價值的神經網絡因輸入輸出中間其他層的存在以及多個神經網絡的相互配合(如transformer模型),將會使得運算量呈指數級增長,并引入除了乘法和加法之外的其他運算過程,因此實際模型中總運算量的計算也會非常復雜,CCL給出的算例僅具有參考價值,在實際合規應當由工程人員結合實際模型結構和BIS提供的指引進行準確計算,不可直接套用前述6ND FLOP的公式。
當然,該算例并非毫無價值,其給出了計算運算量的一般方法的同時,結合技術注釋的其他文本提出了一個重要原則,即運算量的計算是與實際實現和硬件無關的(regardless of the implementation and hardware limitations),無論使用什么樣的硬件平臺或算法,任何實際產生的數學運算都應將計入運算量,應當計入總運算量,除非能夠實際減少運算量,否則僅僅是算子層面的優化并不能規避該閾值。當然,如果通過改進算法,在實際減少了運算量的情況下,達到了與高運算量模型相當的性能的,4E091的注釋2也確保這種模型不會因為其高性能就落入其管制范圍。
(二) 數據處理階段運算量的例外
4E091關于運算的定義中,明確排除了數據收集和預處理階段產生的運算。但也有例外,如果一個模型中超過10%的運算(operations)是基于由同一個數據生成模型生成的非公開合成數據(synthetic data),那么操作這個數據生成模型生成合成數據的運算量(即推理運算量)也應該算在內。如果這個數據生成模型的參數未被公開,那么最初用于訓練這個數據生成模型運算量也應當被計算在內,而這個運算量會比推理運算量大得多。
即如果模型A使用了模型B生成的數據D進行訓練,且基于模型B的輸出進行訓練的運算量超過了其總運算量的10%,則B用于生成D的運算量也應當累加進A中,如果B的參數未被公開(即通常所說的閉源模型),則用于訓練B本身的運算量也應當被計算。
同時,CCL為了防止通過多個變體模型規避掉前述10%的閾值,其規定,基于同一個模型的變體(如不同的檢查點或微調后的版本)生成的數據,視同為同一個模型。還是前面的例子,如果A使用的是B生成的數據D和B的變體B’生成的數據D’進行訓練,只要基于D和D’進行訓練的運算量總和超過了10%,都會觸發前述累加條款。
對于多個未公開的數據生成模型生成的數據共同用于一個模型的訓練,且最終運算量超過10%的,則僅應當計算被用的最多的那個模型的運算量。
CCL中還規定了一個“不重復計算”原則防止運算量虛高,例如,某公司使用數據生成模型A用于訓練模型B和模型C,而B和C生成的數據又用于訓練模型D,則訓練A的運算量只計入模型D的運算量一次。
4
公開參數模型的排除
(一) 一般情形
CCL在4E091的注釋1中,明確排除了已公開參數的模型,根據EAR§ 734.7(a)的定義,公開包含五種情形,對于人工智能模型來說,最常見的為其第一或第四種情形:
(1) 任何希望獲取或購買已發布信息的個人均可無限制地獲取的(Subscriptions available without restriction to any individual who desires to obtain or purchase the published information);
(4) 以任何形式(例如,不一定是出版形式)進行公開傳播(即不受限制地分發),包括在互聯網上發布在對公眾開放的網站上的。[Public dissemination (i.e., unlimited distribution) in any form (e.g., not necessarily in published form), including posting on the Internet on sites available to the public]。
按照前述規定,開源在如Huggingface, Modelscope等人工智能協作平臺的模型,顯然屬于這里的已公開,但對于某些經申請和審批后可獲得的模型(如早期版本的Llama),則因不具備前述規定所述的不受限制性,不屬于這里的已公開模型。
(二) 例外
如基于公開參數模型進行二次訓練得到的模型,通常來說也不在4E091的范圍內,但有一個例外情況,如果二次訓練的運算量超過2.5*10^25或超過模型本身運算量25%(兩者孰高)的,則此時產生的衍生模型可能會重新落入4E091的范圍。此時的模型二次開發者如不想受到EAR對4E091的強管制,一個可行的辦法就是繼續開源基于開源模型訓練后得到的模型。
注釋及參考文獻
[1] https://www.modelscope.cn/models/Qwen/Qwen2.5-7B-Instruct/files
作者簡介
陶冶 國浩南京合伙人
業務領域:軟件和互聯網
郵箱:taoye@grandall.com.cn